Overview
Recently, I started working on our IoT logging platform we built on top of Loki. Something we lacked was fine grained comparisons for events across nodes. We knew going into it that we couldn't absolutely trust machine timestamps, but it would be useful to understand a series of events without needing the overhead of tracing. In order to do that, we had to make sure that clocks were synchronized to a rough degree. We use Prometheus to scrape clock drift, and monitor the machines over time.
Using Time
Ordering Events
In some cases, we may wish to use time to determine happens before relationship for events, some examples might include:
- Determining the order that requests come in
- Ordering logs to figure out the series of events that led to some outcome
- Ordering events in concurrent environments to see if any states prevent progress or correctness.
For example, Linux developers may check the ring buffer to ensure systems are started in the correct order:
~ ❯ sudo dmesg | rg usb
[ 0.447472] usbcore: registered new interface driver usbfs
[ 0.447472] usbcore: registered new interface driver hub
[ 0.447472] usbcore: registered new device driver usbDurations
Other situations may arise that require us to measure the length of some time frame. Some examples of this include:
- Request timeouts
- Cache entry durations
- Span lengths in tracing
A concrete example where durations are used is within DNS clients. When an
authoritative DNS server provides a response to a query, it includes a TTL for
how long we can cache that entry for. systemd-resolved is a common DNS
resolver in Linux based systems. When systemd-resolved gets a response, it
determines how long to cache it for based on the TTL and some other metadata,
and then sets the until field of the entry to a timestamp which consists of
the TTL plus the current timestamp, which is defined as:
timestamp = now(CLOCK_BOOTTIME);For those of you wondering, CLOCK_BOOTTIME is a monotonic clock:
CLOCK_MONOTONIC (and likewise CLOCK_MONOTONIC_COARSE and CLOCK_MONOTONIC_RAW), a
nonsettable clock that represents monotonic time since—as described by
POSIX—"some unspecified point in the past".
CLOCK_BOOTTIME (and likewise CLOCK_BOOTTIME_ALARM), a nonsettable clock that is
identical to CLOCK_MONOTONIC, except that it also includes any time that the
system is suspended.Systemd-resolved periodically checks to see whether that time has elapsed, and flushes the key if so:
/* Remove all entries that are past their TTL */
for (;;) {
DnsCacheItem *i;
char key_str[DNS_RESOURCE_KEY_STRING_MAX];
i = prioq_peek(c->by_expiry);
if (!i)
break;
if (t <= 0)
t = now(CLOCK_BOOTTIME);
if (i->until > t)
break;
// ...
// flushes the entry
}Comparison to some reference time
Finally, in some cases we may desire to compare the current time to some external reference time. Some examples might include:
- Is it time to run my cron job?
- Has my certificate expired?
- Has my GPG key expired?
GPG keys and certificates in general expire according to some reference time. Here is what gpg says about my public key:
~ ❯ gpg --list-keys
pub ed25519 2025-05-15 [C] [expires: 2040-05-11]
BEA79BAAACD3C5CDEDCCABBCB4547B0B29A21703
uid [ultimate] Jacob Deinum <[email protected]>
sub ed25519 2025-05-15 [S] [expires: 2030-05-14]
sub ed25519 2025-05-15 [A] [expires: 2030-05-14]
sub cv25519 2025-05-15 [E] [expires: 2030-05-14]So on those dates at midnight, the keys are no longer valid and should not be used.
Keeping Time
Now that we have a better understanding of the things we use time for, let's take a look at the mechanisms we have to keep track of time. A physical clock is a clock that tracks the number of seconds elapsed, while a logical clock is a software construct that is used to order events. In this section, we'll focus on physical clocks. I plan on writing another article on logical clocks either in parallel or just after I finish this one.
Quartz Crystal Oscillator
For most of us, the mechanism used to keep track of the number of seconds elapsed is a quartz crystal oscillator (QCO). It's been a little while since my last physics class, but I'll try to give a brief overview of how these crystals work. Quartz is an example of a piezoelectric material. When mechanical stress (force) is applied to these materials, an electric charge is generated. The inverse is also true; When an electric charge is applied to the material, a force is generated.
A quartz crystal is cut into a specific shape and size, typically in the form of a thin wafer, using precise methods like a laser or mechanical cutting. When an electric voltage is applied to the crystal, it deforms slightly due to the piezoelectric effect. This deformation changes the shape of the crystal. When the voltage is removed, the crystal attempts to return to its original shape, and this process causes the crystal to vibrate at a very stable frequency. These vibrations (oscillations) are what are used to keep time.
The frequency of oscillation is highly stable, typically accurate to within around 50 parts per million (ppm). This means that over the course of a day, the oscillator could be off by as much as 4.3 seconds (assuming a 24-hour period), or about 50 microseconds per second.
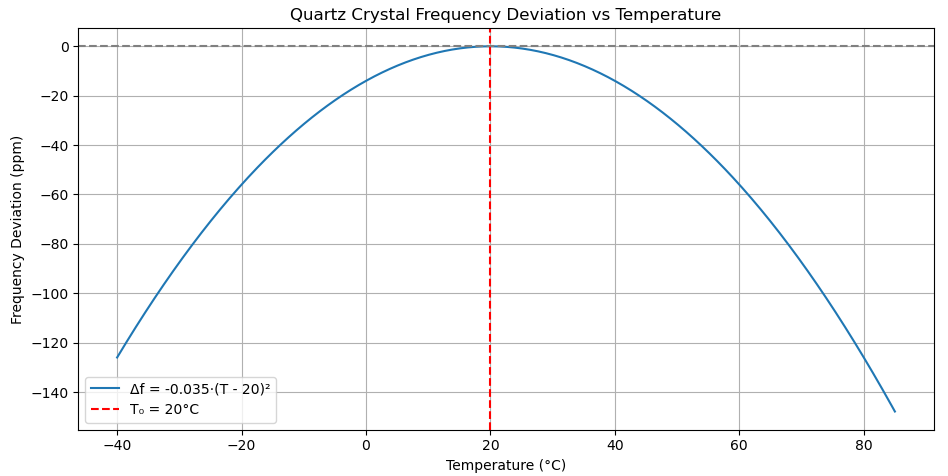
One of the primary problems with QCOs is that their oscillation changes with temperature. The crystals themselves are designed to be the most accurate at room temperature (20 degrees Celsius). Deviating from this temperature results in a quadratic decrease in the clock speed: where ~ 20 degrees Celsius.
What this means is that if your system is under a lot of load, say at or over capacity for the number of requests it can handle per second, the QCO will oscillate at a different frequency and time will appear to move faster than it should:
In Linux systems, we can see the name of our hardware clock by looking in the
/sys directory:
~ ❯ cat /sys/class/rtc/rtc0/name
rtc_cmos rtc_cmosWe can use the hwclock command to interact with our hardware clock, including
syncing with the system time, or getting it to predict its own drift.
~ ❯ sudo hwclock
2025-06-03 09:51:23.637481-06:00Atomic Clocks
For use cases where more accuracy is needed, atomic clocks are an alternative to QCOs that use the transitions of atoms from one energy state to another as a reference.
The basis for atomic clocks is a collection of atoms that can be in one of two energy states. Typically, atoms with very specific and stable energy differences like Cesium-133 are chosen. A number of these atoms are prepared by putting them in the lower energy state. By exposing these atoms to radiation of a particular frequency, we can get the maximum number of atoms transitioning to their higher energy state. By measuring the number of atoms that transitioned between these states, we can determine how close our microwave oscillator is to being the exact frequency of the natural transition of the atom, and make small adjustments if needed. The result is the we can use the microwave oscillator as an extremely stable time source. For Cesium, it oscillates 9,192,631,770 times per second. So we count the number of oscillations and derive elapsed time from that. This is actually how the SI unit second (S) is defined.
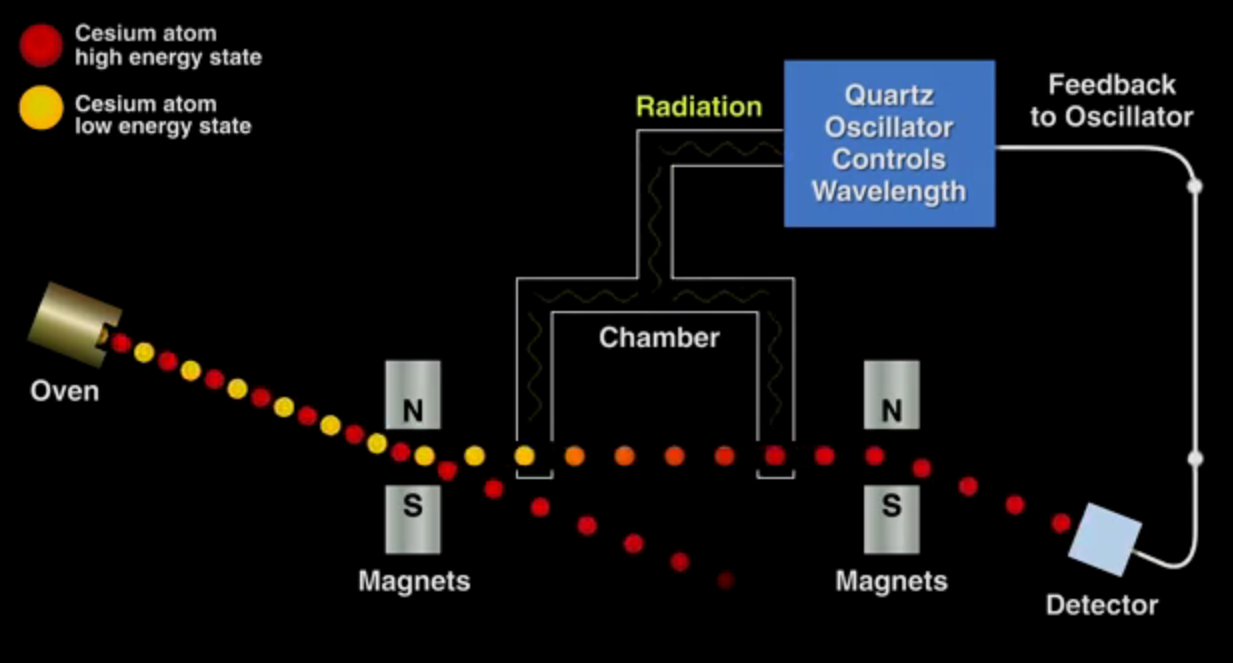
GPS, the system we all know and love consists of a series of satellites around the globe. Each of these satellites contain an atomic clock. Therefore, one option to get time from an atomic clock system is to purchase a GPS receiver that can read these values from the satellite system. Using GPS receivers as PTP grandfather sources is the approach that Jane Street takes.
Atomic clocks are much much more accurate than QCOs. For example, NIST-F2 measures time with an uncertainty of 1 second in 300 million years.
Operating System Clocks
The oscillations produced by your hardware clock source drive a hardware timer that triggers kernel interrupts at set intervals. The kernel uses these interrupts to update both the monotonic and real time clocks.
Monotonic
The monotonic clock is a clock source in Linux that measures the amount of time elapsed since some arbitrary point in time. Typically this when the device boots, but it can vary per platform. Because of this, comparing monotonic timestamps from two different machines typically has no meaning. Another property that monotonic clocks possess is that they are guaranteed to only move forwards.
Monotonic clocks still get adjusted by the Network Time Daemon, but only the rate at which time moves forward is adjusted (no setting the clock to the correct value). Literature has coined the term slewing for this process.
Because the monotonic clocks only move forward, they are well suited to measuring durations. Indeed, libraries like tokio use the monotonic clock to measure durations. Therefore the following is valid:
use std::time::{Duration, Instant};
// ...
let start = Instant::now();
doSomething();
let end = Instant::now();
let diff = end - start; // CORRECT
// (barring that each tick may not be the same length)Real Time Clock
The wall clock, or alternatively the real time clock in Linux is the familiar clock on your computer. It tells you the time in some format that is useful to you. Two common formats within computer systems are:
NOTE: You might run across version like RFC-3339 or RFC-2822. These are implementations of ISO 8601 with slight variations between them.
Under the hood, the real time clock is just stored as a base value
(realtime_offset) that is added to the monotonic clock to get the current real
time. The realtime_offset is calculated at boot using the RTC and some other
info.
Unlike the monotonic clocks, the real time clock does not guarantee that it only moves forward. Services like NTP can forceably set the value of the real time clock at will (although NTP has some restrictions on when it will step the clock). Therefore, the following is not valid:
use std::time::{Duration, SystemTime};
// ...
let start = SystemTime::now();
doSomething();
let end = SystemTime:now();
let diff = end - start; // INCORRECT
// diff can be < 0 if NTP steps the clock during line 4NTP & Clock Synchronization
Now that we understand the two types of clocks on Linux (Real Time & Monotonic), we are ready to move on to NTP, which is a common mechanism used to synchronize clocks to some external source. Before looking at NTP, it's important to understand what we mean by synchronize here. Synchronize in this case refers to:
- Having the value of the clock be close to some desired value (Real time only)
- Having the clock move forward at the correct rate (Real time and Monotonic)
NTP handles both of these cases by stepping the clock (setting its value) and slewing the clock (changing the rate at which it moves forward). I won't go into the detail of how it does this within the kernel, but it's source can be found here. Additionally the official docs are an excellent resource.
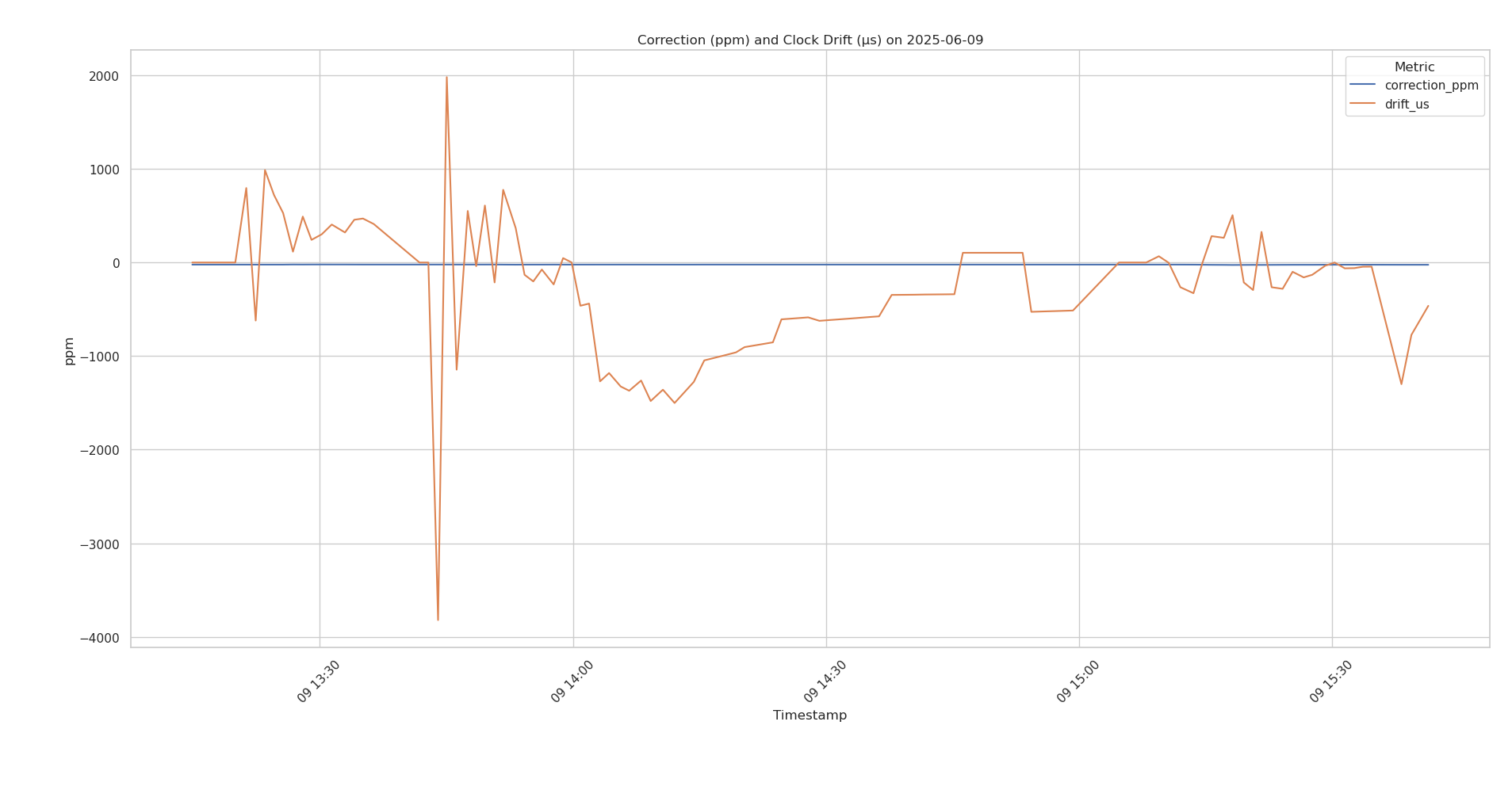
Figure 3 shows both the correction applied to my local clock as well as the
drift from upstream NTP servers. It seems pretty solid. 4000 ppm is 4
milliseconds, so my clock is still working well and the corrections are typically
less than 50ppm. I captured all of the values using chronyc tracking and a
systemd timer to have it run every minute.
Overview
NOTE: There are a few different ways you can run NTP. I'll only be discussing the basic client server model here.
Imagine a world where all network delay is exactly ,and there is no processing delay. In such a world, you can imagine the server determines the clock skew using something similar to the following:
- The NTP client sends a message to the NTP server, including its current time
- The NTP server receives , and replies with its own message including and , where is the servers current timestamp.
- The NTP client records
From these 3 timestamps, we can determine the following:
This is all the info the NTP server needs to tell your clock how to adjust itself (alongside some other info).
Things get a little more tricky when you take away the unrealistic assumptions. We'll instead consider our network link to be fair loss, that is, each message has probability p that it gets dropped, but if you continue retrying, it will eventually succeed. We also introduce processing delays for both parties. Because is no longer constant, we can't calculate these values with just 3 timestamps. NTP works as follows:
- The NTP client sends a request to the NTP server, including its timestamp
- The server records its timestamp T1 when it receives , and sends back which contains ,, where is the timestamp of the server when was sent.
- Finally, the client records , which is the timestamp at which it receives .
From these 4 timestamps, we can calculate the clock skew. Before we can do that however, we need to know the total network delay, i.e the total amount of time our two messages are moving over the network. Ideally we'd like to know the breakdown of how long each message was on the network, but this would require we have synchronized clocks, which we likely don't have. Instead, we'll calculate the total network delay and assume the M1 and M2 have the same network delay (i.e symmetric).
The is the total amount of time the client was waiting until it receives the response, and represents the processing delay on the server.
The first thing we can note is that when the client receives M2, it expects the server clock to be at
And finally, the estimated clock skew would be
Once the NTP client has the clock skew, what it does actually depends on the size of the clock skew.
If the clock skew is <125ms, the ntp client will slew the clock by up to 500ppm
If the clock skew is between 125ms and 1000 seconds, the client will step the clock to the correct value.
If the clock skew is >1000 seconds, it does nothing, because clearly there is something very wrong.
Challenges of Synchronization
Network Delay
While NTP and its younger sibling, PTP, are the defacto solution for synchronizing clocks across a network, they still fall victim to poor networks. If the network delay is highly variable, NTP will likely provide an accurate representation of the clock skew. Consider a simple case where typically the network delay between the client and the server is 100ms (each direction). After the client sends m1, the link between the server and the client becomes saturated and M2 takes 1s to arrive back to the client. Even though in reality our one way travel time is 100ms, NTP will calculate the one way travel time to be 550ms, which will result in our clock being set to an incorrect time.
Do you trust your source?
When NTP clients seek to determine the current real time, it queries an external source for this data. How do we actually know that the source we are querying is trustworthy and not a malicious actor? NTP employs several techniques to help with this.
First, and NTP client is typically configured to query many servers, and algorithms are used remove outliers from this sample. This way if one of your NTP servers is providing nonsensical values, your system still functions correctly.
Secondly, each server can be queried multiple times over a short period to help account for some of the random network error.
Finally, one can look at something like NTS so that you only accept time from an server who you trust.
Users and Time
In some distributed systems, you may not have control over the clocks. Consider phones, which allow users to set their own clocks arbitrarily. In some cases, users themselves may choose to change the time to a purposefully incorrect value. When I was 14, I played a mobile game called smurfs village, a standard base-builder style of game. Impatient me wasn't going to wait a full week just for a bridge to finish building, so I just set my clock forward until it finished, and then reset it to the correct value sometime later. How do you protect against something like this? How do you manage events these devices are producing?
Timer Per CPU
Most CPUs nowadays have a timer per core, x86 has the TSC and AMD has the CNTVCT_EL0 register. How does one provide a consistent time if a task may be scheduled across different cores? Typically the OS is responsible for providing a consistent overlay that processes can use that hides these differences.
Problems of Unsynchronized Clocks
Algorithms That Depend On Synchronized Clocks
One of the main problems with unsynchronized clocks are that many algorithms depend on time for correctness. Consider Kerberos, a network authentication protocol used to provide access to services for services and users. Kerberos assigns tickets that are only valid for some time frame, say 30 minutes. If an actor controlled the clock of either the Kerberos server, or the clock of a service accepting a ticket, you can skew the clocks enough in the past / future to prevent any access to that service. You could also look at it from the other direction, if an adversary managed to capture a valid ticket, he could set the clock so that the ticket is valid indefinitely. A less common problem is where time is used is in seeding PRNGs. If a codebase happens to use a PRNG instead of a secure RNG, then by setting the clock to a preset value may allow the malicious actor to know which values will be generated over time.
Last Write Wins
In some database systems, the result of two concurrent writers for the same key is often settled using the timestamps attached to both of the writes. This strategy is known as last write wins and is highly susceptible to clock skew. If server As clock is far enough behind Bs, then even if A wrote after B, its write would be silently dropped because its time is earlier than that of Bs.
Comments (0)
Loading comments...